3.4.1. Questions
3.4.1.1. Maximum Number of Points with Cost
You are given an m x n integer matrix points (0-indexed). Starting with 0 points, you want to maximize the number of points you can get from the matrix.
To gain points, you must pick one cell in each row. Picking the cell at coordinates (r, c) will add points[r][c] to your score.
However, you will lose points if you pick a cell too far from the cell that you picked in the previous row. For every two adjacent rows r and r + 1 (where 0 <= r < m - 1), picking cells at coordinates (r, c1) and (r + 1, c2) will subtract abs(c1 - c2) from your score where abs(x) is x's absolute value.
Return the maximum number of points you can achieve.
Example 1:
Input: points = [[1,2,3],[1,5,1],[3,1,1]]
Output: 9
Explanation:
The blue cells denote the optimal cells to pick, which have coordinates (0, 2), (1, 1), and (2, 0).
You add 3 + 5 + 3 = 11 to your score.
However, you must subtract abs(2 - 1) + abs(1 - 0) = 2 from your score.
Your final score is 11 - 2 = 9.
Example 2:
Input: points = [[1,5],[2,3],[4,2]]
Output: 11
Explanation:
The blue cells denote the optimal cells to pick, which have coordinates (0, 1), (1, 1), and (2, 0).
You add 5 + 3 + 4 = 12 to your score.
However, you must subtract abs(1 - 1) + abs(1 - 0) = 1 from your score.
Your final score is 12 - 1 = 11
After selecting the cell in each row in turn, the obtained score is actually only related to the total score obtained after selecting the cell in the previous row, so it can be solved by dynamic programming.
Design an array dp[i], which represents the maximum score when the i-th cell of the current row is selected. If the total score of the corresponding position of the previous line is lastLine[i], then dp[i] = max(lastLine[j] - |i - j|) + points[line][i], 0 <= j < n .
In order to simplify the solution, the dynamic programming method can be further optimized to preprocess the calculation of the highest score that can be obtained by selecting the left and right cells of the previous row at each position.
Finally, dp[i] is the highest score obtained when cell i in the last row is selected, and the maximum value is the solution. It should be noted that the data range of this question may exceed MAX_INT.
1typedef long long LL;
2const LL INF = 1e10;
3const int maxn = 1e5 + 10;
4LL dp[2][maxn]; // 利用滚动数组进行优化数组
5struct Solution {
6 long long maxPoints(vector<vector<int>> &points) {
7 int n = points.size(), m = points[0].size();
8 for (int j = 0; j < m; j++)
9 dp[0][j] = points[0][j]; // 第一行本身就是最大得分
10 for (int i = 1; i < n; i++) {
11 int pi = (i - 1) & 1, ni = i & 1; // 滚动数组变换
12 for (int j = 0; j < m; j++) dp[ni][j] = -INF; // 一半滚动数组初始化
13 LL mx = -INF;
14 for (int j = 0; j < m; j++) {
15 mx = max(mx - 1LL, dp[pi][j]);
16 dp[ni][j] = max(dp[ni][j], mx + points[i][j]);
17 }
18 mx = -INF;
19 for (int j = m - 1; j >= 0; j--) {
20 mx = max(mx - 1LL, dp[pi][j]);
21 dp[ni][j] = max(dp[ni][j], mx + points[i][j]);
22 }
23 }
24 LL ans = -INF;
25 for (int j = 0; j < m; j++) ans = max(ans, dp[(n - 1) & 1][j]);
26 return ans;
27 }
28};
3.4.1.2. Regular Expression Matching
Implement regular expression matching with support for “.” and “*”. “.” Matches any single character. “*” Matches zero or more of the preceding element. The matching should cover the entire input string (not partial).
The function prototype should be: bool match(const string& s, const string& p)
Examples:
match("aa", "a") → false
match("aa", "aa") → true
match("aaa","aa") → false
match("aa", "a*") → true
match("aa", ".*") → true
match("ab", ".*") → true because ".*" can be explained as "..", and ".." matches "ab".
match("aab","c*a*b") → true
Without star, the problem is very simple. The only tricky thing is the star. This problem can be solved with a recursive function. Code Block 3.4.2 is a implementation with recursion from head to tail. You can also implement another version with recursion from tail to head, but the code s.substr(0, s.size()-2) will be more lengthy than s.substr(2).
1struct regex_match_rec: public regex_match_base {
2 bool match(const string& s, const string& p) {
3 if (p.empty()) return s.empty();
4 if ('*' == p[1])
5 return match(s, p.substr(2)) or !s.empty() and
6 (s[0] == p[0] or '.' == p[0]) and
7 match(s.substr(1), p);
8 else
9 return !s.empty() and (s[0] == p[0] or '.' == p[0]) and
10 match(s.substr(1), p.substr(1));
11 }
12};
Adding a cache to the recursive approach, we can have a top-down dynamic programming with memoization implementation Code Block 3.4.3.
1struct regex_match_topdown: public regex_match_base {
2 vector<vector<char>> dp;
3 bool match(const string& s, const string& p, int a, int b) {
4 if (dp[a][b] != -1) return dp[a][b];
5 if (p.size()==b) return dp[a][b] = s.size()==a;
6 if ('*' == p[b+1])
7 return dp[a][b] = match(s, p, a, b+2) or a!=s.size() and
8 (s[a] == p[b] or '.' == p[b]) and
9 match(s, p, a+1, b);
10 else
11 return dp[a][b] = a!=s.size() and (s[a] == p[b] or '.' == p[b]) and
12 match(s, p, a+1, b+1);
13 }
14 bool match(const string& s, const string& p) {
15 dp = vector<vector<char>>(s.size() + 1, vector<char>(p.size() + 1, -1));
16 return match(s, p, 0, 0);
17 }
18};
We can try bottom-up approach as Code Block 3.4.4.
1struct regex_match_bottomup: public regex_match_base {
2 bool match(const string &s, const string &p) {
3 const int M = s.size(), N = p.size();
4 vector<vector<bool>> dp(M + 1, vector<bool>(N + 1));
5 dp[0][0] = true;
6 for (int i = 1; i <= N; ++i)
7 if (p[i - 1] == '*' and i >= 2) dp[0][i] = dp[0][i - 2];
8 for (int i = 1; i <= M; i++) {
9 for (int j = 1; j <= N; j++) {
10 if (p[j - 1] == s[i - 1] or p[j - 1] == '.') {
11 dp[i][j] = dp[i - 1][j - 1];
12 } else if (p[j - 1] == '*') {
13 dp[i][j] =
14 (j >= 2 and dp[i][j - 2]) or
15 ((s[i - 1] == p[j - 2] or p[j - 2] == '.') and dp[i - 1][j]);
16 }
17 }
18 }
19 return dp[M][N];
20 }
21};
The time complexity is O(M*N), where M and N are the length of string s and p respectively. But which method is the fastest?
Code Block 3.4.5 has two test cases with profiling code.
1void test(shared_ptr<regex_match_base> sln, const string& test_name) {
2 auto_profiler ap(test_name);
3 string s = string(1024, 'a') + "mississippi";
4 string p = "aaa.aaa*mis*is*p*.";
5 EXPECT_FALSE(sln->match(s, p));
6 s = string(1024, 'a'), p = "a*a.";
7 EXPECT_TRUE(sln->match(s, p));
8}
9TEST(_regex_match, a) {
10 test(make_shared<regex_match_rec>(), "recursive");
11 test(make_shared<regex_match_topdown>(), "top-down");
12 test(make_shared<regex_match_bottomup>(), "bottom-up");
13}
We can see, from Code Block 3.4.6, the top-down approach actually is the fastest, and bottom-up is the slowest. The reason is because, in this problem, top-down approach doesn’t calculate all the subproblems in the subproblem space. It only calculatea the necessary nodes in the subproblem graph. In this specific case, only the 10% and 80% subproblems are calculated in the first and second test cases respectively. This is the advantage of recursion and top-down approaches over bottom-up approach. However, if, in other problems, all the subproblems need to be calculated, the bottom-up approach will be normally faster since it has less overhead like function call.
recursive : 1665 us
top-down : 441 us
bottom-up : 2440 us
3.4.1.3. Wildcard Matching
Given an input string (s) and a pattern (p), implement wildcard pattern matching with support for ‘?’ and ‘*’ where: ‘?’ Matches any single character. ‘*’ matches any sequence of characters (including the empty sequence). The matching should cover the entire input string (not partial). s contains only lowercase English letters. p contains only lowercase English letters, ‘?’ or ‘*’.
💡 The biggest difference between wild card matching and regular matching is in the rules for the use of stars. For regular matching, the star cannot exist alone, and there must be a character in front of it, and the meaning of the star is to indicate the number of characters in front of it. The number can be any number, including 0, so it doesn’t matter even if the previous character does not appear in s, as long as the latter can be matched. This is not the case for wild card matching. The star has nothing to do with the previous characters in wildcard matching. If the previous characters do not match, then return false directly, and don’t care about the star at all. The role of the star is that it can represent any string, of course, only when the matching string is missing some characters. When the matching string contains characters that the target string does not have, it will not match successfully.
1struct wildcard_matching_rec {
2 bool match(const string& s, const string& p) {
3 if (p.empty()) return s.empty();
4 if (s.empty()) return p[0] == '*' and match(s, p.substr(1));
5 if (p[0] == '?')
6 return match(s.substr(1), p.substr(1));
7 else if (p[0] == '*')
8 return match(s.substr(1), p) or match(s, p.substr(1));
9 else
10 return p[0] == s[0] and match(s.substr(1), p.substr(1));
11 }
12};
💣 line 4: to match empty s, p could be empty or a sequence of continuous stars.
We can add cache to recursive solution to get the top-down dynamic programming solution. The same as the Section 3.4.1.2, this problem doesn’t need the entire subproblem space being solved. Tthe top-down dynamic programming code is as Code Block 3.4.8. It is just some base cases plus recursion logic with results being cached. You even don’t have to think about the meaning of the cache. But if you have to, cache[i][j] means the result of match(s[i:], p[j:]).
1struct wildcard_matching_topdown {
2 vector<vector<char>> cache;
3 bool dp(const string& s, const string& p, int x, int y) {
4 if (cache[x][y] != -1) return cache[x][y];
5 if (y == p.size()) return cache[x][y] = (x == s.size());
6 if (x == s.size())
7 return cache[x][y] = (p[y] == '*' and dp(s, p, x, y + 1));
8 if (p[y] == '?')
9 return cache[x][y] = dp(s, p, x + 1, y + 1);
10 else if (p[y] == '*')
11 return cache[x][y] = dp(s, p, x + 1, y) or dp(s, p, x, y + 1);
12 else
13 return cache[x][y] = (p[y] == s[x] and dp(s, p, x + 1, y + 1));
14 }
15 bool match(const string& s, const string& p) {
16 cache = vector<vector<char>>(s.size() + 1, vector<char>(p.size() + 1, -1));
17 return dp(s, p, 0, 0);
18 }
19};
To have a bottom-up solution, you have to define the cache thoughtfully. The the bottom-up solution is Code Block 3.4.9.
1struct wildcard_matching_bottomup {
2 bool match(const string& s, const string& p) {
3 int M = s.size(), N = p.size();
4 vector<vector<bool>> cache(M + 1, vector<bool>(N + 1));
5 cache[0][0] = true;
6 for (int i = 1; i <= N; ++i)
7 if (p[i - 1] == '*') cache[0][i] = cache[0][i - 1];
8 for (int i = 1; i <= M; ++i) {
9 for (int j = 1; j <= N; ++j) {
10 if (p[j - 1] == '*') {
11 cache[i][j] = cache[i - 1][j] or cache[i][j - 1];
12 } else if (p[j - 1] == s[i - 1] or p[j - 1] == '?') {
13 cache[i][j] = cache[i - 1][j - 1];
14 } // else => false
15 }
16 }
17 return cache[M][N];
18 }
19};
In the bottom-up approach, cache[i][j] means s[0:i) matches p[0:j), so i and j are equivalent to the string length.
3.4.1.4. Subsequence Number
Given two strings, find the number of times the second string occurs in the first string, whether continuous or discontinuous.
3.4.1.5. Longest Increasing Subsequence(LIS)
Given an unsorted array of integers, find the length of longest increasing subsequence.
For example, Given [10, 9, 2, 5, 3, 7, 101, 18], The longest increasing subsequence is [2, 3, 7, 101], therefore the length is 4. Note that there may be more than one LIS combination, it is only necessary for you to return the length.
👽 Could you improve it to \(O(NlogN)\) time complexity?
3.4.1.6. Number of Longest Increasing Subsequence(LIS)
3.4.1.7. Longest Common Subsequence
3.4.1.8. Edit Distance (Levenshtein distance)
3.4.1.9. Burst Balloons
3.4.1.10. Paint House
3.4.1.11. House Robber
3.4.1.12. Dungeon Game
3.4.1.13. Target Sum
3.4.1.14. Maximal Square
3.4.1.15. Count Subarrays With More Ones Than Zeros
3.4.1.16. Longest String Chain
You are given an array of words where each word consists of lowercase English letters.
wordA is a predecessor of wordB if and only if we can insert exactly one letter anywhere in wordA without changing the order of the other characters to make it equal to wordB.
For example, "abc" is a predecessor of "abac", while "cba" is not a predecessor of "bcad".
A word chain is a sequence of words [word1, word2, ..., wordk] with k >= 1, where word1 is a predecessor of word2, word2 is a predecessor of word3, and so on. A single word is trivially a word chain with k == 1.
Return the length of the longest possible word chain with words chosen from the given list of words.
Example 1:
Input: words = ["a","b","ba","bca","bda","bdca"]
Output: 4
Explanation: One of the longest word chains is ["a","ba","bda","bdca"].
Example 2:
Input: words = ["xbc","pcxbcf","xb","cxbc","pcxbc"]
Output: 5
Explanation: All the words can be put in a word chain ["xb", "xbc", "cxbc", "pcxbc", "pcxbcf"].
Example 3:
Input: words = ["abcd","dbqca"]
Output: 1
Explanation: The trivial word chain ["abcd"] is one of the longest word chains.
["abcd","dbqca"] is not a valid word chain because the ordering of the letters is changed.
1#include <gtest/gtest.h>
2
3#include <sein.hpp>
4
5namespace ns_dp_lsc {
6
7int longestStrChain(vector<string>& words) {
8 int n = words.size(), res = 1;
9 sort(words.begin(), words.end(),[](string& a, string& b) { return a.size() < b.size(); });
10 unordered_map<string, int> dp;
11 for (string word : words) {
12 dp[word] = 1;
13 for (int i = 0; i < word.size(); ++i) {
14 string pre = word.substr(0, i) + word.substr(i + 1);
15 if (dp.count(pre)) {
16 dp[word] = max(dp[word], dp[pre] + 1);
17 res = max(res, dp[word]);
18 }
19 }
20 }
21 return res;
22}
23
24class Solution {
25bool pred_v2(const string& a, const string& b){// is a pred of b without considering order
26 int cc[128]={};
27 for(char c:a) cc[c]++;
28 for(char c:b) cc[c]--;
29 int r=0;
30 for(int i=0;i<128;i++) r+=cc[i];
31 return r==-1;
32}
33bool pred(const string& a, const string& b){// is a pred of b considering order
34 for(int i=0;i<b.size();i++){
35 string t=b;
36 t.erase(i,1);
37 if(t==a) return true;
38 }
39 return false;
40}
41public:
42int longestStrChain(vector<string>& words) {
43 map<int, vector<string>> m; // {{1,{'a','b'}},{2,{'ba'}}}
44 unordered_map<string, int> mx; //
45 for(auto s: words) m[s.size()].push_back(s), mx[s]=1;
46 int res=1;
47 for (auto& [sz, vs]: m) {
48 if (m.count(sz-1)) {
49 auto& v = m.at(sz-1);
50 for(auto& str: vs){ // O(N)
51 for(auto& z: v) { // O(N)
52 if(pred_v2(z, str)) {
53 mx[str]=max(mx[str], mx[z]+1);
54 res = max(res, mx[str]);
55 }
56 }
57 }
58 }
59 }
60 return res;
61}
62};
63} // namespace ns_dp_lsc
64
65using namespace ns_dp_lsc;
66TEST(_dp_lsc, a) {
67 vector<string> vs={"a","bda","bdca","b","ba","bca"};
68 EXPECT_EQ(longestStrChain(vs), 4);
69 vs = {"abcd","dbqca"};
70 EXPECT_EQ(longestStrChain(vs), 1);
71 EXPECT_EQ(Solution().longestStrChain(vs), 2);
72}
3.4.1.17. Warehouses In Villages
There are several villages on a one-dimensional axis, and several warehouses can be built in the axis. The cost of each village is the square of the distance from the village to its nearest warehouse. Find the minimum sum of cost of building k warehouses in between u villages.
3.4.1.18. Maximum Profit in Job Scheduling
We have n jobs, where every job is scheduled to be done from startTime[i] to endTime[i], obtaining a profit of profit[i].
You're given the startTime, endTime and profit arrays, return the maximum profit you can take such that there are no two jobs in the subset with overlapping time range.
If you choose a job that ends at time X you will be able to start another job that starts at time X.
Example 1:
Input: startTime = [1,2,3,3], endTime = [3,4,5,6], profit = [50,10,40,70]
Output: 120
Explanation: The subset chosen is the first and fourth job.
Time range [1-3]+[3-6] , we get profit of 120 = 50 + 70.
Example 2:
Input: startTime = [1,2,3,4,6], endTime = [3,5,10,6,9], profit = [20,20,100,70,60]
Output: 150
Explanation: The subset chosen is the first, fourth and fifth job.
Profit obtained 150 = 20 + 70 + 60.
Example 3:
Input: startTime = [1,1,1], endTime = [2,3,4], profit = [5,6,4]
Output: 6
Maintain a increasing max-profit-til-time sequence(using list or map), so we can do binary search.
end3
..._________|
end2
..._______|
|____________|
(start4) (end4)
<------------------ We need to find the end time which is `the last less than or equal to` start4 (end3 in this case).
upper_bound is used to find the last of less-than-or-equal-to element.
1#include <gtest/gtest.h>
2#include <sein.hpp>
3
4namespace ns_dp_job_sched{
5struct Solution { // TC: O(NLogN)
6 int jobScheduling(vector<int> startTime, vector<int> endTime, vector<int> profit) {
7 vector<array<int,3>> jobs;
8 for (int i = 0; i < profit.size(); i++) jobs.push_back({startTime[i], endTime[i], profit[i]});
9 sort(jobs.begin(), jobs.end(), [](const array<int,3>& a, const array<int,3>& b){
10 return a[1] < b[1]; }); // 💣 sort by end_time
11 map<int, int> m={{0,0}}; // end_time -> max profit until time
12 for(auto [start, end, p]: jobs){
13 // 💣 `it` is the greatest key less than or equal to the given key
14 auto it = prev(m.upper_bound(start)); // last_less_than_or_equal_to
15 int val = p + it->second;
16 if(val > m.rbegin()->second) m[end] = val;
17 }
18 return m.rbegin()->second;
19 }
20};
21
22struct Solution_LIST { // TC: O(NLogN)
23 int jobScheduling(vector<int> startTime, vector<int> endTime, vector<int> profit) {
24 vector<tuple<int,int,int>> jobs;
25 for (int i = 0; i < profit.size(); i++) jobs.push_back({startTime[i], endTime[i], profit[i]});
26 sort(jobs.begin(), jobs.end(), [](tuple<int,int,int>& a, tuple<int,int,int>& b){
27 return get<1>(a) < get<1>(b); // 💣 sort by end_time
28 });
29 int res = 0;
30 list<pair<int, int>> l={{0,0}}; // end_time -> max profit until time
31 for(auto [start, end, p]: jobs){
32 auto it = prev(upper_bound(l.begin(), l.end(), pair<int,int>({start,INT_MAX})));
33 res=max(res, p + it->second), l.emplace_back(end, res);
34 }
35 return res;
36 }
37};
38}
39using namespace ns_dp_job_sched;
40TEST(_ns_dp_job_sched, a) {
41 vector<int> startTime={1,2,3,3}, endTime={3,4,5,6}, profit={50,10,40,70};
42 EXPECT_EQ(Solution().jobScheduling(startTime, endTime, profit), 120);
43 EXPECT_EQ(Solution().jobScheduling(
44 {1,2,3,4,6}, {3,5,10,6,9}, {20,20,100,70,60}), 150);
45 EXPECT_EQ(Solution_LIST().jobScheduling(startTime, endTime, profit), 120);
46 EXPECT_EQ(Solution_LIST().jobScheduling(
47 {1,2,3,4,6}, {3,5,10,6,9}, {20,20,100,70,60}), 150);
48}
3.4.1.19. Longest Increasing Subsequence(LIS)
Given an unsorted array of integers, find the length of longest increasing subsequence. For example, given [10, 9, 2, 5, 3, 7, 101, 18], the longest increasing subsequence is [2, 3, 7, 101], therefore the length is 4. Note that there may be more than one LIS combination, it is only necessary for you to return the length. Your algorithm should run in O(N^2) complexity.
Follow up: Could you improve it to O(NLogN) time complexity?
There are two solutions for LIS: DP and patience sort. For DP, the recurrence function is:
dp[x] = max(dp[x], dp[y] + 1) where y < x and nums[y] < nums[x]
Patience sorting is a sorting algorithm inspired by, and named after, the card game patience. A variant of the algorithm efficiently computes the length of a longest increasing subsequence in a given array. https://en.wikipedia.org/wiki/Patience_sorting
Take array {6, 3, 5, 10, 11, 2, 9, 14, 13, 7, 4, 8, 14} as an example.
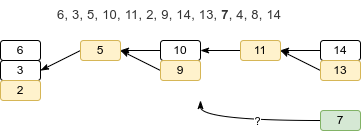
Figure 3.4.1 Patience Sort with Binary Search
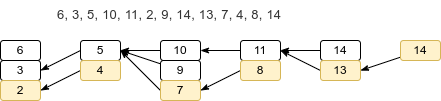
Figure 3.4.2 Patience Sort with TC: O(NLogN)
The number of the piles is the longest increasing subsequence.
1#include <gtest/gtest.h>
2#include <sein.hpp>
3
4namespace ns_lis {
5int LIS_DP(vector<int> nums) {
6 if (nums.empty()) return 0;
7 vector<int> dp(nums.size(), 1);
8 for (int i = 1; i < nums.size(); ++i)
9 for (int j = i - 1; j >= 0; --j)
10 if (nums[i] > nums[j])
11 dp[i] = max(dp[j] + 1, dp[i]);
12 return *max_element(dp.begin(), dp.end());
13}
14
15int LIS_Patience_Set(vector<int> nums) {
16 set<int> st;
17 set<int>::iterator it;
18 for (int i: nums) {
19 it = st.lower_bound(i);
20 if (it != st.end())
21 st.erase(it);
22 st.insert(i);
23 }
24 return st.size();
25}
26
27int LIS_Patience_List(vector<int> nums) {
28 list<int> l;
29 for (int i: nums) {
30 auto it = lower_bound(l.begin(), l.end(), i);
31 if (it != l.end()){
32 l.insert(l.erase(it), i); // 💣 replace in list
33 } else l.push_back(i);
34 }
35 return l.size();
36}
37}
38using namespace ns_lis;
39TEST(_ns_lis, a) {
40 EXPECT_EQ(LIS_Patience_List({6, 3, 5, 10, 11, 2, 9, 14, 13, 7, 4, 8, 14}), 6);
41 EXPECT_EQ(LIS_DP({3, 4, -1, 0, 6, 2, 3}), 4);
42 EXPECT_EQ(LIS_Patience_Set({3, 4, -1, 0, 6, 2, 3}), 4);
43 EXPECT_EQ(LIS_Patience_Set({6, 3, 5, 10, 11, 2, 9, 14, 13, 7, 4, 8, 14}), 6);
44 EXPECT_EQ(LIS_Patience_Set({6, 6, 6, 6}), 1);
45}
3.4.1.20. Russian Doll Envelopes
You are given a 2D array of integers envelopes where envelopes[i] = [wi, hi] represents the width and the height of an envelope. One envelope can fit into another if and only if both the width and height of one envelope are greater than the other envelope’s width and height. Return the maximum number of envelopes you can Russian doll (i.e., put one inside the other). Note: You cannot rotate an envelope.
Example 1:
Input: envelopes = [[5,4],[6,4],[6,7],[2,3]]
Output: 3
Explanation: The maximum number of envelopes you can Russian doll is 3 ([2,3] => [5,4] => [6,7]).
Example 2:
Input: envelopes = [[1,1],[1,1],[1,1]]
Output: 1
The problem boils down to a two dimensional version of the longest increasing subsequence problem (LIS). We must find the longest sequence seq such that the elements in seq[i+1] are greater than the corresponding elements in seq[i] (this means that seq[i] can fit into seq[i+1]). The problem we run into is that the items we are given come in arbitrary order - we can’t just run a standard LIS algorithm because we’re allowed to rearrange our data. How can we order our data in a way such that our LIS algorithm will always find the best answer?
We answer the question from the intuition by sorting. Let’s pretend that we found the best arrangement of envelopes. We know that each envelope must be increasing in w, thus our best arrangement has to be a subsequence of all our envelopes sorted on w. After we sort our envelopes, we can simply find the length of the longest increasing subsequence on the second dimension (h). Note that we use a clever trick to solve some edge cases: Consider an input [[1, 3], [1, 4], [1, 5], [2, 3]]. If we simply sort and extract the second dimension we get [3, 4, 5, 3], which implies that we can fit three envelopes (3, 4, 5). The problem is that we can only fit one envelope, since envelopes that are equal in the first dimension can’t be put into each other. In order fix this, we don’t just sort increasingly in the first dimension - we also sort decreasingly on the second dimension, so two envelopes that are equal in the first dimension can never be in the same increasing subsequence. Now when we sort and extract the second element from the input we get [5, 4, 3, 3], which correctly reflects an LIS of one.
1#include <gtest/gtest.h>
2#include <sein.hpp>
3
4namespace ns_russian_doll {
5// TC: O(N^2)
6struct Solution_DP {
7 int maxEnvelopes(vector<vector<int>>& envelopes) {
8 int L=envelopes.size();
9 sort(envelopes.begin(), envelopes.end(), [](const vector<int>& a, const vector<int>& b){
10 return a[0]<b[0] or (a[0]==b[0] && a[1]<b[1]);
11 });
12 vector<int> r(L+1, 1);
13 for(int i=1;i<L;i++){
14 for(int j=0;j<i;j++){
15 if(envelopes[i][0]>envelopes[j][0] and envelopes[i][1]>envelopes[j][1]){
16 r[i]=max(r[i], r[j]+1);
17 }
18 }
19 }
20 return *max_element(r.begin(), r.end());
21 }
22};
23// TC: O(NLogN)
24struct Solution_Patience {
25 int maxEnvelopes(vector<vector<int>> envelopes) {
26 auto comp = [](const vector<int>& a, const vector<int>& b){
27 return a[0]<b[0] or (a[0]==b[0] && a[1]>b[1]); // 💣 first is increasing, second decreasing
28 };
29 sort(envelopes.begin(), envelopes.end(), comp);
30 list<vector<int>> l;
31 auto comp2 = [](const vector<int>& a, const vector<int>& b){
32 return a[0]<b[0] and a[1]<b[1]; // 💣
33 };
34 for(auto& vi: envelopes){
35 auto it = lower_bound(l.begin(), l.end(), vi, comp2);
36 if (it==l.end())
37 l.push_back(vi);
38 else
39 l.insert(l.erase(it), vi); // 💣 replace in list
40 }
41 return l.size();
42 }
43};
44}
45using namespace ns_russian_doll;
46TEST(_russian_doll, a) {
47 vector<vector<int>> m={{5,4}, {6,4}, {6,7}, {2,3}};
48 EXPECT_EQ(Solution_Patience().maxEnvelopes(m), 3);
49 EXPECT_EQ(Solution_DP().maxEnvelopes(m), 3);
50 EXPECT_EQ(Solution_Patience().maxEnvelopes({{5,4}, {6,4}, {6,7}, {2,3}, {6,5}}), 3);
51}
3.4.1.21. Maximum Height by Stacking Cuboids
Given n cuboids where the dimensions of the ith cuboid is cuboids[i] = [width_i, length_i, height_i] (0-indexed). Choose a subset of cuboids and place them on each other. You can place cuboid i on cuboid j if width_i <= width_j and length_i <= length_j and height_i <= height_j. You can rearrange any cuboid’s dimensions by rotating it to put it on another cuboid.
Return the maximum height of the stacked cuboids.
Input: cuboids = [[50,45,20],[95,37,53],[45,23,12]]
Output: 190
Explanation:
Cuboid 1 is placed on the bottom with the 53x37 side facing down with height 95.
Cuboid 0 is placed next with the 45x20 side facing down with height 50.
Cuboid 2 is placed next with the 23x12 side facing down with height 45.
The total height is 95 + 50 + 45 = 190.
1#include <gtest/gtest.h>
2#include <sein.hpp>
3
4namespace ns_stacking_cuboids {
5struct Solution { // TC: O(36*N^2)
6 int maxHeight(const vector<vector<int>>& cuboids) {
7 vector<array<int, 4>> cs; // 💣
8 for(int i=0;i<cuboids.size();i++){
9 for(auto vi: perm(cuboids[i])){
10 cs.push_back({vi[0],vi[1],vi[2],i});
11 }
12 }
13 sort(cs.begin(), cs.end()); // 💣
14 vector<int> dp(cs.size());
15 for(int i=0;i<cs.size();i++){
16 dp[i]=cs[i][2];
17 for(int j=i-1;j>=0;j--){
18 if(cs[j][0]<=cs[i][0] and cs[j][1]<=cs[i][1] and cs[j][2]<=cs[i][2] and cs[j][3]!=cs[i][3]) {
19 dp[i]=max(dp[i], dp[j]+cs[i][2]);
20 }
21 }
22 }
23 return *max_element(dp.begin(), dp.end());
24 }
25 vector<vector<int>> perm(vector<int> vi){
26 vector<vector<int>> r;
27 vector<int> p;
28 vector<bool> visited(vi.size());
29 dfs(r, p, vi, visited);
30 return r;
31 }
32 void dfs(vector<vector<int>> &r, vector<int>& p, vector<int>& vi, vector<bool>& visited){
33 if(p.size()==vi.size()) {r.push_back(p); return;}
34 for(int i=0;i<vi.size();i++){
35 if(visited[i]) continue;
36 visited[i]=true, p.push_back(vi[i]);
37 dfs(r,p,vi,visited);
38 visited[i]=false, p.pop_back();
39 }
40 }
41};
42struct Solution_V2 { // TC: O(N^2)
43 int maxHeight(vector<vector<int>> cuboids) {
44 for(int i=0; i<cuboids.size(); i++)
45 sort(cuboids[i].begin(), cuboids[i].end());
46 sort(cuboids.begin(), cuboids.end()); // 💣
47 vector<int> dp(cuboids.size());
48 for(int i=0;i<cuboids.size();i++){
49 dp[i]=cuboids[i][2];
50 for(int j=i-1;j>=0;j--){
51 if(cuboids[j][0]<=cuboids[i][0] and cuboids[j][1]<=cuboids[i][1] and cuboids[j][2]<=cuboids[i][2]) {
52 dp[i]=max(dp[i], dp[j]+cuboids[i][2]);
53 }
54 }
55 }
56 return *max_element(dp.begin(), dp.end());
57 }
58};
59}
60using namespace ns_stacking_cuboids;
61TEST(_stacking_cuboids, a) {
62 vector<vector<int>> m={{50,45,20}, {95,37,53}, {45,23,12}};
63 EXPECT_EQ(Solution().maxHeight(m), 190);
64 EXPECT_EQ(Solution_V2().maxHeight(m), 190);
65}