2.3.1. Questions
2.3.1.1. Linked List Cycle
Given a linked list, determine if it has a cycle in it.
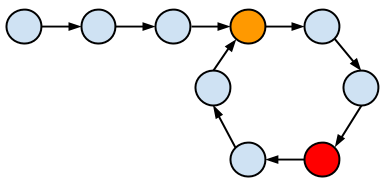
Figure 2.3.1 Use Floyd’s Tortoise And Hare Algorithm To Detect Cycle
1 bool hasCycle(ListNode *head) {
2 ListNode *slow=head, *fast=head;
3 while(fast && fast->next){ // dont have to check slow
4 slow=slow->next;
5 fast=fast->next->next;
6 if(slow==fast) return true;
7 }
8 return false;
9 }
Given a linked list, return the node where the cycle begins, like node Y in Figure 2.3.2. If there is no cycle, return null.
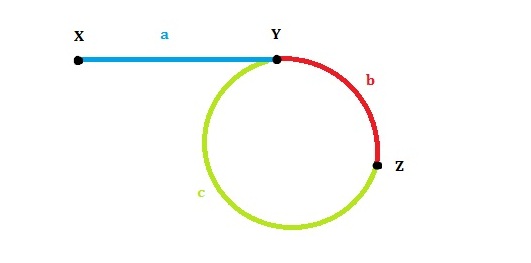
Figure 2.3.2 Find Where The Cycle Begins
Proof: The tortoise moves d = a + b + N L , hare moves two times as tortoise 2 d = a + b + M L , so d = ( M − N ) L = a + b + N L , and a + b = ( M − 2 N ) L . M − 2 N is an positive integer. So at point Z, if tortoise moves a step, it will get point Y. a is not necessarily equal to c, but what we can guarantee is that starting from Z, one will reach Y after a steps(although it is possible that one has circled for several rounds).
1ListNode *detectCycle(ListNode *head) {
2 if (!head || !head->next) return nullptr;//
3 ListNode *t=head, *h=head; // t is tortoise and h is hare
4 while(h && h->next){
5 t=t->next, h=h->next->next;
6 if(t==h) break;
7 }
8 if(t!=h) return 0;
9 t=head; // put tortoise back to the list head
10 while(t != h)
11 t=t->next, h=h->next;
12 return t; // When they meet again, it is at point Y
13}
2.3.1.2. Linked List Random Node
Given a singly linked list, return a random node’s value from the linked list. Each node must have the same probability of being chosen.
Follow up: What if the linked list is extremely large and its length is unknown to you? Could you solve this efficiently without using extra space?
This is related to Reservoir Sampling.
1class Solution {
2 ListNode *head;
3public:
4 Solution(ListNode* head) :head(head) {}
5 int getRandom() {
6 int ans = 0;
7 ListNode *p = head;
8 for (int cnt = 1; p; cnt++, p = p->next)
9 if (rand() % cnt == 0)
10 ans = p->val;
11 return ans;
12 }
13};
2.3.1.3. Merge K Sorted Lists
Merge k sorted linked lists and return it as one sorted list. Analyze and describe its complexity.
TC: O(NlogK), SC: O(K) where N is total number of Nodes and K is number of lists
1class Solution {
2 struct comp{ // comparator for min-heap
3 bool operator () (ListNode* lhs, ListNode* rhs){
4 return lhs->val > rhs->val;
5 }
6 };
7public:
8 ListNode* mergeKLists(vector<ListNode*>& lists) {
9 if(lists.size() == 0) return nullptr;
10 ListNode dummy(-1);
11 ListNode *p = &dummy;
12 priority_queue<ListNode*,vector<ListNode*>,comp> pq;
13 for(ListNode *head : lists)
14 if(head != nullptr) pq.push(head);
15 while(!pq.empty()){
16 ListNode* node = pq.top(); pq.pop();
17 p->next = node;
18 if(node->next != nullptr)
19 pq.push(node->next);
20 p = p->next;
21 }
22 return dummy.next;
23 }
24};
2.3.1.4. Tweets Diversification
Given a list of tweets sorted by scores descendingly with their corresponding scores and authors, transform the list such that consecutive tweets cannot be from the same author whenever possible. Always prefer the author whose tweets have the highest score if there are multiple possible authors to be considered.
Conditions: 0.0 < Score <= 1.0
Each tuple (score, authorId) represents a tweet. Input is a list of tweets with authors ranked in some initial ordering. The output is a list of tweets such that tweets by the same author are not together.
Example 1
Input: rankedTweetList = [(.6, "A"), (.5, "A"), (.4, "B"), (.3, "B"), (.2, "C"), (.1, "C")]
Output:rankedTweetListAfterDiversity = [(.6, "A"), (.4, "B"), (.5, "A"), (.3, "B"), (.2, "C"), (.1, "C")]
Example 2
Input: rankedTweetList = [(.5, "A"), (.4, "A"), (.3, "A"), (.2, "B"), (.1, "A")]
Output: rankedTweetListAfterDiversity = [(.5, "A"), (.2, "B"), (.4, "A"), (.3, "A"), (.1, "A")]
1vector<pair<double, char>> reorder(vector<pair<double, char>> tweets){
2 list<pair<double, char>> extra;
3 vector<pair<double, char>> result;
4 for(int i=0;i<tweets.size();i++){
5 if (result.empty()){
6 result.push_back(tweets[i]);
7 continue;
8 }
9 if(result.back().second == tweets[i].second){
10 extra.push_back(tweets[i]); // add 5A into extra list
11 }else{ // 4B
12 result.push_back(tweets[i]); // 6A 4B
13 if(not extra.empty() and result.back().second != extra.front().second){ //
14 result.push_back(extra.front()); // 6A 4B 5A
15 extra.erase(extra.begin());
16 }
17 }
18 }
19 for(auto i: extra) result.push_back(i);
20 return result;
21}
👽 Follow up: how to make the result as diverse as possible?
Data Structure:
- heap tree (weight, as meidan+.001*number of tweets, other metrics) + map
- round-robin map
// A -> 0.6, 0.5
// B -> 0.4
// C -> 0.5,0,3
// D -> 0.00002
- kv cache like redis
- LRU cahce read/written by app server